I recently had a request to remove part of a text field from MySQL, JSON data but stored as text in MySQL 5.6.
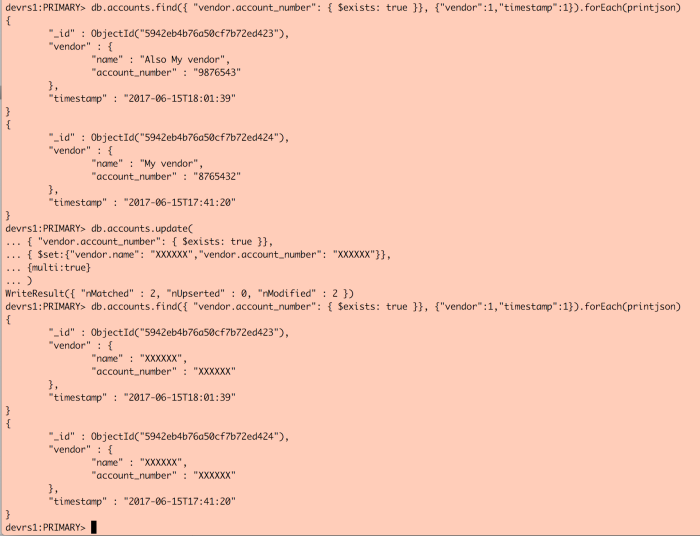
Has this been Mongo, this could have been a pretty quick update of the data within an array:
- Find the data
db.accounts.find({ “vendor.account_number”: { $exists: true }}, {“vendor”:1,”timestamp”:1}).forEach(printjson)
- Update the data
db.accounts.update(
{ “vendor.account_number”: { $exists: true }},
{ $set:{“vendor.name”: “XXXXXX”,”vendor.account_number”: “XXXXXX”}}, {multi:true}
) 
On MySQL, this was a bit trickier. I was able to pull out the segment to be updated using SUBSTRING. Once I was able to identify the SUBSTRING values, I used REPLACE with SUBSTRING_INDEX for the substitution “from” values.
- SUBSTRING_INDEX Syntax: SUBSTRING_INDEX(str,delim,count)
- My data had variable length fields, but were consistent on the prefix for the data, and the character immediately at the end of the section:
- SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1)
- str = request (my column)
- delim = “vendor”:{“name”:”‘ — name was potentially used in more locations, so the longer string
- count = -1
-
“If count is positive, everything to the left of the final delimiter (counting from the left) is returned. If count is negative, everything to the right of the final delimiter (counting from the right) is returned”
-
- REPLACE Syntax: REPLACE(str,from_str,to_str)
- Since my data varied on each record, I had to create a new “from string” to match. I set the update on the same column twice as I was running multiple modifications.
- REPLACE(request, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1),'”,’,1), ‘XXXXXXXX’)
- str = request — my column
- from_str = SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1),'”,’,1) — my string subsection, variable by row
- to_str = ‘XXXXXXXX’ — my replacement/”to” value
- REPLACE(request, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1),'”,’,1), ‘XXXXXXXX’)
- Since my data varied on each record, I had to create a new “from string” to match. I set the update on the same column twice as I was running multiple modifications.
- Find the data
SELECT id
, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1),'”,’,1) AS vendor_name_part
, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”account_number”:”‘, -1),'”}’,1) AS account_number_part
, request
FROM call_logs
WHERE request LIKE ‘%vendor%account_number%’; - Update the data
UPDATE call_logs
SET request = REPLACE(request, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”vendor”:{“name”:”‘, -1),'”,’,1), ‘XXXXXXXX’),
request = REPLACE(request, SUBSTRING_INDEX(SUBSTRING_INDEX(request, ‘”account_number”:”‘, -1),'”}’,1), ‘XXXXXXXX’)
WHERE request LIKE ‘%vendor%account_number%’;
Before the update:

After the update: